Unlike JMS consumers, Kafka consumers need group id. Why? Let's start the analysis from JMS consumers. JMS supports both queue and topic as follows,
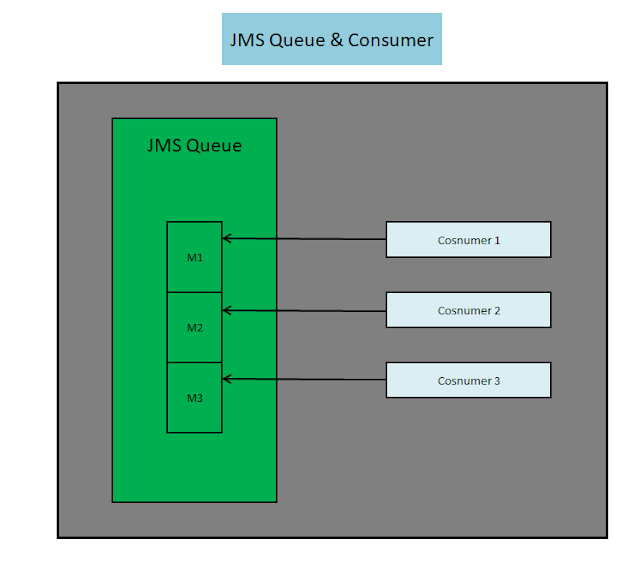
- point-to-point queue with multiple consumers, each of which receives a subset of the messages in the queue.
- publisher subscriber topic with multiple consumers, each of which receives a full copy of all the messages in the topic.
JMS queue obviously has the advantage of load balancing in message consumption, while a topic has the advantage of supporting multiple subscribers. Now the question is how we combine JMS queue and topic into a single message model(without a separate queue and topic) with the advantage of both load balancing and multiple subscribers. With the introduction of group id, this objective is achieved in kafka.
Specifically, a kafka consumer group is composed of one or more consumers with the same group id, and each consumes a subset of the messages based on kafka topic partition. Moreover, in Kafka, multiple groups of consumers can be created with a topic. To conclude, a single kakfa group of consumers works like a JMS queue and multiple groups, each is composed of multiple consumers, work like JMS topic in the way that each group gets a full copy of messages..
It is important to note that the group id of a kafka consumer group must be unique. If two subscribers from two different teams subscribe to the same topic with the same group id, it may ends up with one subscriber getting a subset of the messages and another subscriber receiving the remaining messages. One way to solve the uniqueness issue is to control group id through boarding process.
The following are diagrams that show how the consumers of JMS topic and queue and Kafka topic work.


Specifically, a kafka consumer group is composed of one or more consumers with the same group id, and each consumes a subset of the messages based on kafka topic partition. Moreover, in Kafka, multiple groups of consumers can be created with a topic. To conclude, a single kakfa group of consumers works like a JMS queue and multiple groups, each is composed of multiple consumers, work like JMS topic in the way that each group gets a full copy of messages..
It is important to note that the group id of a kafka consumer group must be unique. If two subscribers from two different teams subscribe to the same topic with the same group id, it may ends up with one subscriber getting a subset of the messages and another subscriber receiving the remaining messages. One way to solve the uniqueness issue is to control group id through boarding process.
The following are diagrams that show how the consumers of JMS topic and queue and Kafka topic work.

JMS Queue and Consumer

JMS Topic and Consumer

Kafka Consumer
Comments
Post a Comment