Apache Nifi and System Integration
Introduction
Apache Nifi is a distributed data platform based on enterprise integration pattern(EIP). It is a very powerful tool to build data pipeline with its large number of built-in processors.In today's service orientated architecture or a system composed of micro services, the flow of data among systems is fundamental in building enterprise applications. Among integration tools (Mule ESB, Apache Camel, Apache Nifi), Nifi is my favorite due to its built-in processors, ease to use and dynamic/hot redeployment, all leading to high productivity. When it is used together with Kafka connector, we can build real time CDC(change data capture) bi-direction integration system. This feature is especially useful in application re-engineering and migration.Nifi Basics
Unlike camel, Nifi is a web based integration tool where you configure your processors, the building block of Nifi, to pilepine your data from your source system to your target system. Data, which is wrapped in an "envelope" called "flowfile" that is composed of meta data and payload, flows from one processor to another processor, ending finally in a destination system. Suppose we have data in a kafka queue and we want to transform and enrich the data and persist it to Mongodb. The following diagram shows how it works. The ConsumeKafka processor reads messages from Kafka queue; the ExcecuteScript processors handles transformation and enrichment; PutMongo processor persists the data into Mongodb. All three processors are built in and all you need to write your transformation and enrichment logic in the ExecuteScript processor using scripts like clojure, python, groovy, lua and ruby.

Nifi Architecture: Distributed but Masterless
Nifi is a distributed, but masterless system. Nifi can be deployed as standalone as well as cluster which is usually composed 3 or more nodes. The data in the form of flowfiles is distributed to nodes in your cluster for load balancing. This distributed feature makes nifi scales well in a production environment. Unlike hbase that has a master to coordinate region servers and to execute administrative tasks in a cluster, nifi does not have a master. Instead, it uses a coordinator node to handle administrative tasks. For the example, the coordinator node replicates all your processor configurations to other nodes.The coordinator node is selected when nifi is started. And the coordinator node can be re-elected when necessary or current coordinator node is down.Why Primary Node?
When you schedule the job for a Nifi processor, you can assign the job to run in all nodes or in primary node only. If you select to run in all nodes in the nifi cluster, your Nifi flowfiles are distributed to all nodes to achieve better scalability. However, in a distributed environment, the data that is modified earlier may ends up being processed later, leading to inconsistent data. In order to guarantee that messages or flowfiles are processed in the same order as they are generated, Nifi introduces primary node in which all messages are processed in the same primary node. This way, data corruption is prevented. If you want to have better scalability as well data consistency, you can assign a version id or event time for each of your messages and in our last processor, you can compare the version id against the last version id of the same data in your data store to determine whether you need to keep it or not.
The rule:Never use both primary node mode and all nodes mode in the same processor group because data could end up in one processor without moving to the next one.
The rule:Never use both primary node mode and all nodes mode in the same processor group because data could end up in one processor without moving to the next one.
Guaranteed Delivery VS Fault Tolerance
HBase, with its distributed architecture and data replication, provides fault tolerance. Nifi handles this with guaranteed delivery or loss tolerance. Each Nifi node persists its flowfiles to disk. When a node in a cluster is down, all new flowfiles will be routed to other live nodes. The unprocessed data will be reprocessed when the failed node is restarted. So there is no data loss in a distributed Nifi cluster. There is a road map to implement fault tolerance in Nnifi.
Back Pressure
Back pressure is useful when one processor generates lots of data while the next processor is not able to consume the data fast enough, which usually leads to out of memory or performance degradation issues. With back pressure support, Nifi can block the previous processor from generating new flowfiles when the configured threshold is reached. Nifi supports back pressure through two configured parameters (Object Threshhold vs Size Threshold) as follows,

Cluttered UI and Processor Group
When you have many different types of data to process, it means you need to create many processors to transform your data. And Nifi is ui based and it's very hard to put all your processors in a single ui. To solve this issue, Nifi provides hierarchical processor groups to gracefully organize your processors. The following two diagrams shows how processor groups work.
Processor Groups

Individual Group Processors

The Most Widely Used Processor
The most widely used built-in processor is probably ExecuteScript processor which handles data transformation and enrichment. This processor allows you to write transformation and enrichment logic in any of the following supported script languages.
- Clojure
- ECMAScript
- Groovy
- Lua
- Ruby
- Python
The script can be written either inline or in a file. This is how the processor looks like.
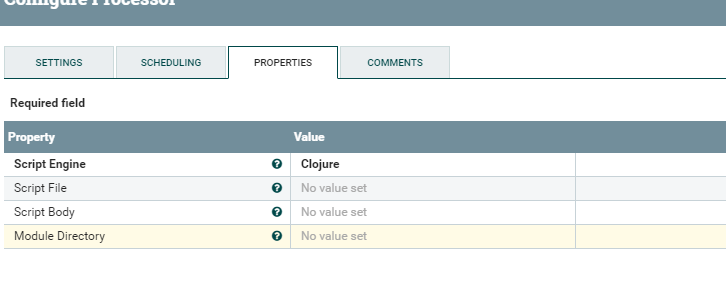
If you don't like script languages, Nifi gives you the option to develop your own processor in java where you can implement your business logic.
Flow.xml.gz
All of your flow configurations(processors, processor groups, controller service) put in the ui are written into the location of /nifiroot/conf folder. In a cluster environment, each node has it own copy of this file. If you get your flow.xml.gz file corrupted in one or more nodes in the cluster, you can simply delete the corrupted file and restart the nodes. This will sync the good flow.xml.gz from other nodes to your current node. Nifi also archives the flow.xml.gz file. In case all your flow.xml.gz files are corrupted in all nodes, you can find the latest good one in the archive directory from one of the nodes and roll back to the desired version.
Code Reuse
Code reuse is very important in application development. There are a few ways to use code in Nifi.
- Create templates from existing processors or processor groups. Once a template is created, it can be added to other dataflows from Nifi UI.
- Simply copy/paste an existing processor or processor group and then modify it based on your new requirements.
- Shared processor through shared output port and input port. Use shared output port and shared input port so as to share the same processor for data from multiple processor groups or connections.
- Shared processor through Nifi funnel.
Nifi Flow Deployment
A common question for Nifi development is how to deploy the files from your development environment to your production environment. There are the following ways of deployment
- Nifi registry that was introduced since Nifi 1.6.
- Check Nifi flow.xm.gz or template files into version control tool like Git.
Each approach has its pros and cons. The first approach requires an installation of Nifi registry and the deployment from development environment to product environment is seamless and may not require a post-deployment server restart. The second option has the benefits of integrating your nifi flow deployment with your company's existing deployment system.
Develop Your Own Processors
Nifi comes with lots of built-in processors. However, there might be still scenarios that you need to develop your own processors in the following cases.
- Nifi does not have the processor you require.
- The existing processor does not completely fit your request.
In the first case, we can create a new processor, and for the second case, we can rewrite an existing processor into a new processor with your custom logic. It is easy and convenient to write your own processor. In most cases, we extend the existing Nifi org.apache.nifi.processor.AbstractProcessor class to add our own functionalities for our new processor. It is very important to note that Nifi processors are used in multi-thread environment and your processors must be thread-safe. Moreover, the processor is packaged as a Nifi archive(nar) to provide a type of classloader isolation to resolve dependency conflicts. To deploy your own processor nar, simply drop the nar to a newly created lib directory and configure the nifi.properties to point to the new lib folder. For simplicity, you can also put it in the /nifihome/lib folder. The key point is the new nar file must be deployed to all nodes in your cluster.
Nifi Community and Support
In Hortonworks community, Nifi is one of the most popular technologies, second only to Hadoop. Hortonworks community support for Nifi is very good. I could get answers back in 3-4 hours after I posted my questions. Moreover, Nifi itself has been active in development. When I started in using Nifi in early 2018, its version was 1.4 and now its latest version was 1.8.
Reference
- https://nifi.apache.org/developer-guide.html
- https://nifi.apache.org/docs.html
Comments
Post a Comment